We live in an age flooded with information. New technologies are making available many large unstructured sets of information. As this information becomes more available, it becomes more difficult to navigate without a guide. Now that a typical user can carry around 10,000 songs in his pocket, the choice of picking which song to listen to becomes increasingly more difficult. Now that a typical user can access 13 billion websites, how does a person know which sites are relevant to him?
The solution to this problem resides in building new web-based technologies that aid in the formation of folksonomies. Folksonomy is commonly defined as a large group of people spontaneously cooperating to organize information into categories [24]. Many websites today are taking advantage of the organizational powers of folksonomies, such as Wikipedia, Flickr, Technorati, Del.icio.us, Yahoo!, and others. All of these sites employ a simple tagging mechanism, where users attribute words or phrases to content. When these tags are aggregated, new metadata for that content is created.
Tagging offers amazing possibilities for information retrieval by using collective social intelligence to organize information instead of relying on one person’s description or categorization. However, tagging only begins to approximate an ideal folksonomy. By simplifying the ways in which we collect metadata from the user, coupling this information collection more strongly with a social framework, and providing more powerful tools for categorization, we should be able to greatly improve systems for retrieving relevant information. (
Full paper found here)
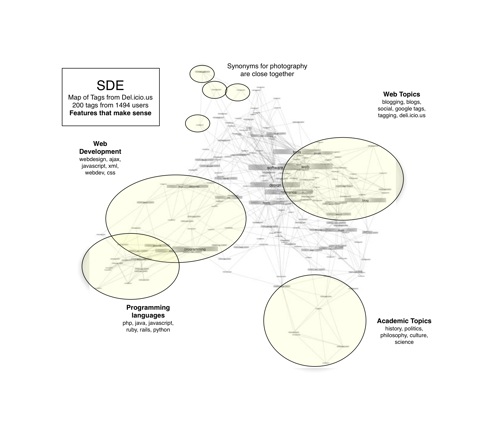
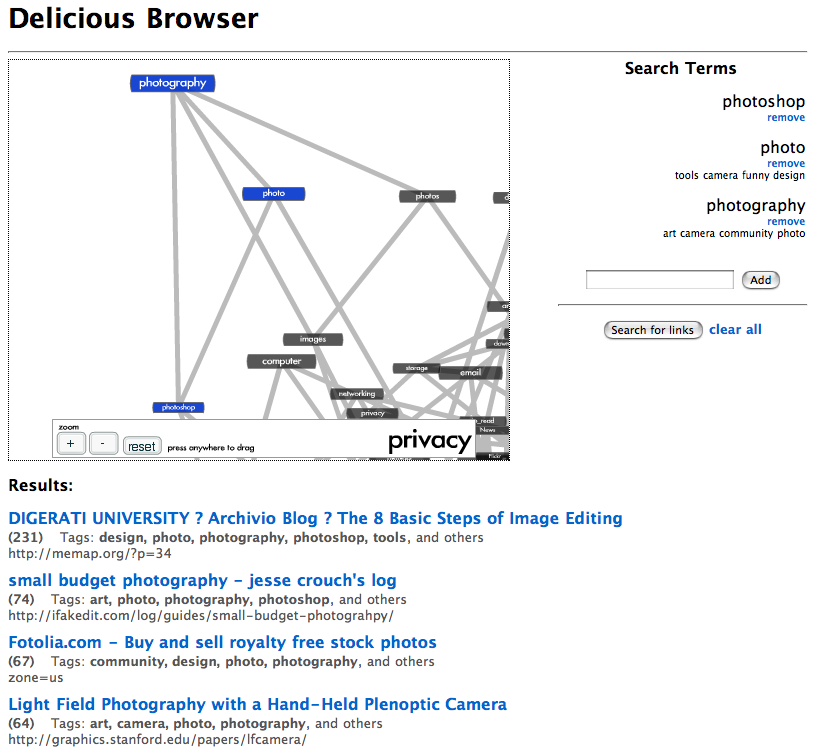
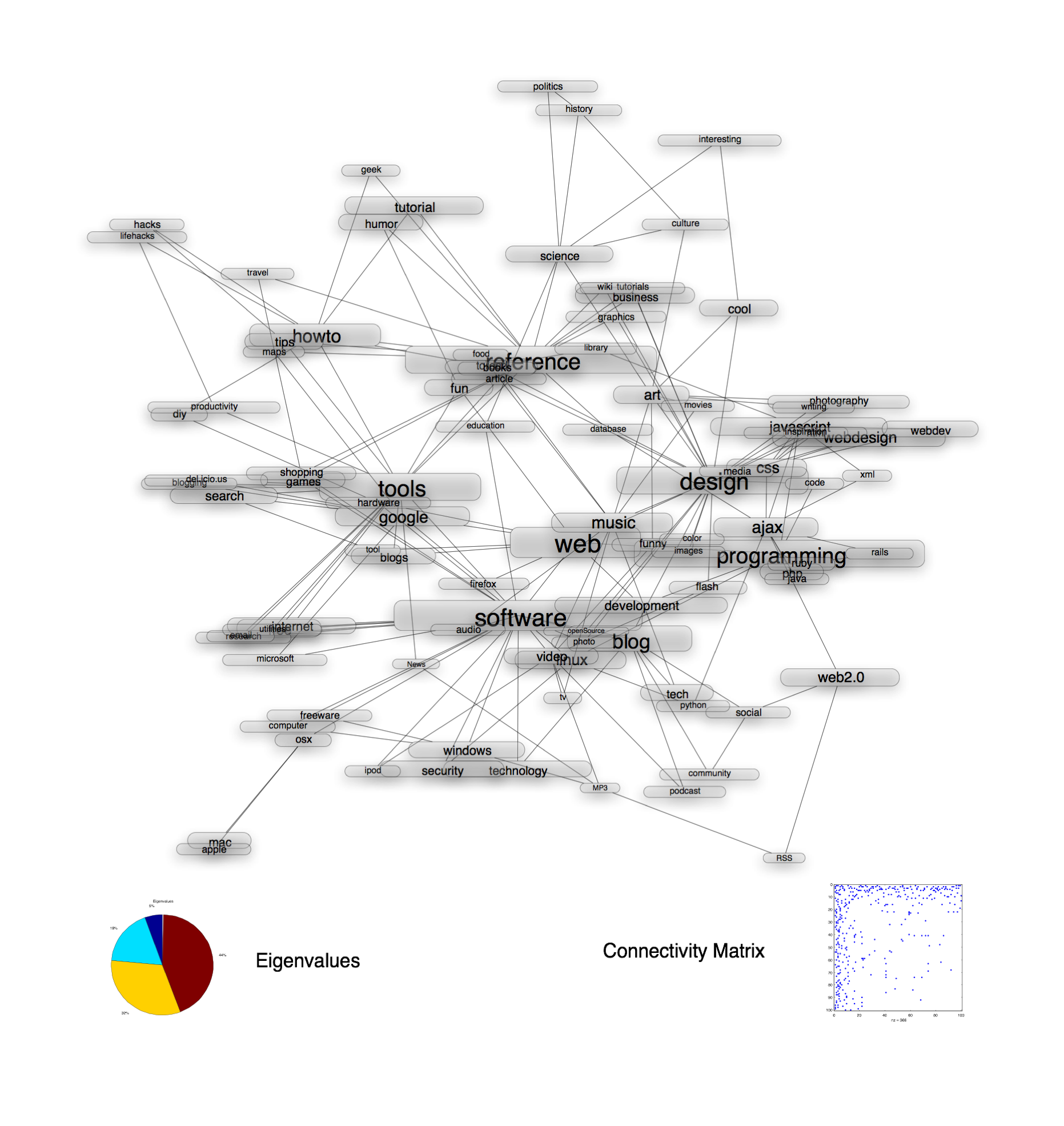 This paper, written for my Adv. Machine Learning class, investigates using Semidefinite Embedding (SDE) to visualize data collected from a folksonomy. The del.icio.us social bookmarking service is a perfect example of a folksonomy; a community of users label websites with descriptive tags. Each tag exists in a high-dimensional space corresponding to the frequency of use of that tag among all the users of the system. We are motivated by the following question: can we find a simple low-dimensional structure for these tags that captures the significant relationships inherent in the data? In this paper we explore Semidefinite Embedding, an algorithm for non-linear dimensionality reduction, and its application to visualizing folksonomic systems, focusing on the effects of specifying different levels of connectivity for the data and the heuristics which can be used to find the best parameters for the algorithm. (Full paper found here)
This paper, written for my Adv. Machine Learning class, investigates using Semidefinite Embedding (SDE) to visualize data collected from a folksonomy. The del.icio.us social bookmarking service is a perfect example of a folksonomy; a community of users label websites with descriptive tags. Each tag exists in a high-dimensional space corresponding to the frequency of use of that tag among all the users of the system. We are motivated by the following question: can we find a simple low-dimensional structure for these tags that captures the significant relationships inherent in the data? In this paper we explore Semidefinite Embedding, an algorithm for non-linear dimensionality reduction, and its application to visualizing folksonomic systems, focusing on the effects of specifying different levels of connectivity for the data and the heuristics which can be used to find the best parameters for the algorithm. (Full paper found here)